Chapitre 1
Les types de données
Par Michael Castello
Adapté par Jean-Hugues Roy
Il est important de connaître les différents types de données et de savoir ce qu'il est possible de faire avec chacun afin de collecter les données qui correspondent le mieux à vos besoins. Plusieurs typologies existent. Nous en avons choisi une, que nous allons conserver tout au long de cet ouvrage. Dans cette typologie, quatre grands niveaux de mesure sont définis : les données nominales, les données ordinales, les données d'intervalle et les données de proportion.
Niveaux de mesure
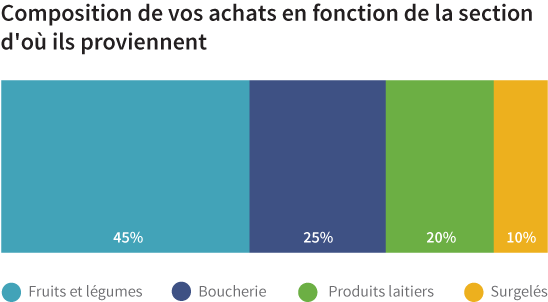
Vous avez certainement remarqué, lorsque vous faites vos emplettes au supermarché, que les produits sont répartis dans différents rayons. Vous pouvez, par exemple, commencer par les fruits et légumes. Vous irez peut-être prendre quelques viandes au comptoir boucherie et charcuterie. Vous prendrez sans doute du pain au rayon boulangerie, du fromage et du yaourt au rayon des produits laitiers. Enfin, il est possible que vous terminiez par quelques surgelés. Une fois à la caisse, vous aurez donc plusieurs produits dans votre panier. Tous pourront être classés dans une catégorie correspondant aux rayons où vous les aurez pris. Ces catégories sont des données qu'on dit « nominales ». Du latin nomen, qui signifie « nom », les données nominales sont des données qu'on ne peut pas placer en ordre. D'un point de vue mathématique, les fruits et légumes ne sont pas supérieurs ou inférieurs aux viandes.
Données nominales
Les données nominales peuvent être comptées et on peut s'en servir pour calculer des pourcentages. Mais il est impossible de faire une moyenne à partir de données nominales. Ainsi, vous pouvez compter le nombre de produits que vous avez achetés dans la section des produits laitiers, par exemple, ou calculer quel pourcentage représentent les fruits et légumes sur l'ensemble de vos achats. Mais vous ne pouvez pas faire la moyenne des différentes sections du supermarché.
Dans les cas où vous n'avez que deux catégories dans votre jeu de données, on dit que vous avez des données dichotomiques. C'est le cas, par exemple, des données relatives à des questions auxquelles il n'est possible de répondre que par oui ou par non. Dans votre panier d'épicerie, vous auriez également pu classer vos achats en fonction du fait qu'ils étaient, ou non, en solde. Si vous l'aviez fait, vous auriez généré des données dichotomiques.
Données ordinales
Mais revenons au supermarché. Vous vous apprêtez à passer à la caisse. Il y a du monde et vous devrez faire la queue. Quelle caisse choisir? Sans compter précisément le nombre de clients dans chacune des queues, vous les classez mentalement en fonction du temps d'attente que vous estimez. Puis, vous choisissez celle où ce temps sera le plus court. Cette caractéristique (le temps d'attente) est une donnée ordinale. Vous pouvez placer les caisses en ordre : de celle où le temps d'attente sera le plus long à celle où il sera le plus court. Un sondage d'opinion qui vous demande si vous êtes « très favorable », « favorable », « sans opinion », « défavorable » ou « très défavorable » recueille des données ordinales. Chacune de ces cinq opinions n'est pas une valeur mathématique en elle-même, mais on peut les placer en ordre. D'ailleurs, les sondeurs attribuent à ces opinions des nombres afin de faciliter la saisie de données et le traitement des réponses (on pourra mettre 5 pour une opinion « très favorable » et 1 pour une opinion « très défavorable ». Mais ces nombres sont arbitraires et on pourrait très bien inverser les attributions et donner la cote de 1 pour une opinion « très défavorable » et de 5 pour une opinion « très favorable ».

Comme pour les données nominales, vous pouvez compter les données ordinales et vous en servir pour calculer des pourcentages. Il y a cependant un débat quant à savoir s'il est possible ou non de faire la moyenne. Pour certains, il est tout simplement impossible de faire la moyenne entre « très favorable » et « défavorable » ou entre « favorable » et « neutre ». Ces catégories ne sont pas des nombres. On peut les remplacer par des nombres, mais ces derniers ne sont qu'une autre façon de donner un nom à vos catégories; ils n'ont pas de véritable sens mathématique.
Pour d'autres, s'il existe une gradation plus ou moins régulière entre les différentes catégories (par exemple, si la différence entre « favorable » et « neutre » est la même qu'entre « neutre » et « défavorable »), il est alors possible de calculer une moyenne avec ces données.
Données d’intervalle
Assez parler des données ordinales...Retournons au supermarché. Vous faites la queue depuis un moment déjà et vous consultez votre montre. Il est 11h30 et vous attendez depuis 11h15. Les heures sont une donnée qu'on dit d'intervalle, car les unités de mesure sont équidistantes, c’est-à-dire que l’intervalle est le même entre chacun des points pouvant être mesurés. Comme chaque minute compte 60 secondes, la différence entre 11h15 et 11h30 est la même qu'entre 12h30 et 12h45, par exemple.
Il est possible d'effectuer des opérations mathématiques à partir de données d'intervalle. Mais il ne faut jamais oublier qu'elles n'ont pas de “vrai” zéro. Dans les cas des heures, par exemple, 00h00 ne veut pas dire qu'il y a une absence de temps. C’est seulement le début d’une nouvelle journée. Même chose avec les températures : lorsqu'on passe de 5 à 10 degrés, on ne peut pas dire que la température a doublé. Et une température de zéro ne représente pas une absence de chaleur.
Données de ratio
Votre montre indique 11h30 et vous vous dites : « J'attends déjà depuis 15 minutes? » Cette donnée (15 minutes d'attente) est une donnée qu'on dit de ratio. Les données de ratio ressemblent aux données d’intervalles, mais, contrairement à ces dernières, elles possèdent un “vrai” zéro, c’est-à-dire que le zéro indique une valeur nulle. Dans une donnée de ratio, le zéro signifie réellement l'absence de quelque chose. Avant que vous vous mettiez à attendre, votre temps d'attente était de zéro seconde. Si vous avez zéro produit laitier dans votre panier, c'est qu'il n'y a réellement aucun produit laitier.
Les données d'intervalle et de ratio peuvent être discrètes ou continues. Une donnée discrète se compte avec des nombres entiers et ne peut pas se briser en fractions. Le nombre de personnes qui fait la queue avec vous est discret : il ne peut pas y avoir un tiers de client. On peut calculer une moyenne de 4,25 clients dans chaque queue, mais le nombre de clients dans chacune doit être entier. Une donnée continue peut prendre n’importe quelle valeur sur une échelle donnée. Normalement, l’échelle a une limite inférieure et une limite supérieure; toutes les valeurs ne sont pas nécessairement possibles. Vous pouvez attendre 7,5 minutes ou acheter un breuvage de 1,5 litres. Il est plus difficile d’attendre -3.5 minutes. Même si l’échelle de temps n’inclut pas les valeurs négatives, on parle quand même de données continues.
Afin de réviser ce qu'on vient d'apprendre, voici le reçu de vos achats au supermarché. Pouvez-vous identifier les éléments qui sont des données nominales, ordinales, d'intervalle et de ratio?
| Date: 23 sept. 2014 Heure: 11h32 | ||||
|---|---|---|---|---|
| Article | Rayon | Allée | Quantité | Prix (€) |
| Oranges—kg | Produits laitiers | 4 | 2 | 2.58 |
| Pommes—kg | Produits laitiers | 4 | 1 | 1.29 |
| Camembert—kg | Surgelés | 7 | 1 | 3.49 |
| Lait—entier—litre | Surgelés | 8 | 1 | 4.29 |
| Petits pois—sac | Boucherie | 15 | 1 | 0.99 |
| Haricots—sac | Boucherie | 15 | 3 | 1.77 |
| Tomates | Fruits et légumes | 2 | 4 | 3.92 |
| Poitrines de poulet | Fruits et légumes | 3 | 2 | 2.38 |
| Champignons | Fruits et légumes | 2 | 5 | 2.95 |
Types de données ou types de variables
Sur le web ou dans des ouvrages spécialisés, les variables sont généralement décrites comme faisant partie de l'un ou l'autre des quatre types vus ci-dessus. Il faut toutefois noter que les variables ne sont pas exclusivement d'un type ou de l'autre. Ce qui détermine le type de données est bien souvent lié à la façon dont la donnée a été collectée.
Prenez l'âge. L'âge est souvent collecté comme une donnée de ratio, mais aussi comme une donnée ordinale. Si on demande dans un sondage : « Quel âge avez-vous? », on recueillera des données de ratio. Si on demande plutôt : « Dans quel groupe d'âge vous situez-vous? » et qu'on offre différents choix de réponse (18-24, 25-34, etc), on recueillera alors des données ordinales. La même variable conduit à différents types de données en fonction de la méthode de cueillette.
Règle générale, il est possible de reculer dans les niveaux de mesure, mais pas d'avancer. Cela veut dire que si vous recueillez des données d'intervalle et de ratio, vous pouvez également les recueillir comme des données nominales ou ordinales. Cependant, si une variable ne peut être que nominale, comme les rayons du supermarché, par exemple, il est impossible de la recueillir comme une donnée ordinale, d'intervalle ou de ratio. Quant au variables qui sont intrinsèquement ordinales, elles ne peuvent être recueillies comme ratio ou intervalle, mais peuvent très bien devenir nominales. Toutefois, plusieurs des variables recueillies comme ordinales ont une variable similaire qui peut être collectée comme intervalle ou ratio comme le montre le tableau suivant.
| Type de variable ordinale | Corresponding Données d’intervalle/Données de ratio Level Measure | Exemple |
|---|---|---|
| Rang | Type de mesure sur lequel est basé le rang | Enregistrez le temps des coureurs dans une course, plutôt que leur seul rang |
| Échelle | Nombre lui-même | Enregistrez l'âge d'une personne, plutôt que son groupe d'âge |
| Échelle de substitution | Nombres à partir desquels on a construit cette échelle | Enregistrez la note chiffrée d'un étudiant (88%), plutôt qu'une note lettrée (B+) |
Rappelez-vous que la règle générale que nous venons d'énoncer s'applique également dans les étapes d'analyse et de présentation visuelle de vos données. Si vous récupérez une variable faite de données de ratio, il vous sera toujours possible, à une étape ultérieure, de faire des regroupements qui vous permettront de mieux la présenter. Mais l'inverse ne sera pas possible. Par exemple, si vous recueillez l'âge de vos répondants dans un sondage, vous pourrez toujours présenter vos données de façon continue, regroupée par catégories ou en faisant des moyennes. Mais si vous demandez à vos répondants à quel groupe d'âge ils appartiennent, vous ne pourrez pas « revenir en arrière » et calculer l'âge moyen de vos répondants.
Quand c’est possible, vous devriez toujours recueillir vos données au plus haut niveau de mesure possible. Il n’y a rien de plus frustrant que de se rendre compte que vous ne pouvez pas faire la visualisation que vous voulez parce que vous n'avez pas le bon type de données.
Autres termes importants
Si vous lisez d’autres articles ou livres sur les données, vous rencontrerez d'autres façons de les décrire dont nous ne nous servirons pas dans cet ouvrage. Il n'y a pas d'unanimité sur la typologie des données et nous en avons choisi une. Nous vous en parlons et nous en faisons une brève définition ci-dessous afin que vous soyez au courant de leur existence si vous les rencontrez dans d'autres publications.
Données catégorielles
Quand nous avons décrit les données nominales et ordinales, nous avons dit qu'elles permettaient toutes deux de classer vos données en différentes catégories. Certains auteurs regroupent ces deux types en un seul : les « données catégorielles » (ou « catégoriques »). Ils font cependant une distinction entre les données catégorielles ordonnées (données ordinales) et non-ordonnées (données nominales). D'autres auteurs donnent aux données nominales le nom de « catégorielles » et utilisent les deux termes comme des synonymes. Cependant, ils les distinguent des données ordinales, comme nous le faisons.
Données qualitatives et quantitatives
Grosso modo, les « données quantitatives » sont des données qu'on peut quantifier ou calculer. Elles son faites de nombres. Celles qu’on ne peut pas quantifier sont appelées « données quanlitatives ». Ce sont des données qui ne sont pas numériques. Un certain consensus existe quant à l'utilisation de ces termes. Certaines données sont toujours qualitatives, comme les observations directes sur le terrain ou les entrevues dirigées ou semi-dirigées en sciences sociales. D'autres sont toujours quantitatives, comme les données d'intervalle et de ratio, puisqu'elles sont toujours faites de nombres. Il peut y avoir débat en ce qui concerne les données nominales et ordinales. Pour certains, il s'agit de données qualitatives, puisqu'elles classent les données en catégories qui sont essentiellement descriptives. D'autres affirment que, puisque ce type de données peut être utilisé pour calculer des pourcentages, voire des moyennes, il s'agit de données quantitatives.
Afin d'éviter toute confusion, nous nous en tiendrons aux quatre niveaux de mesure que nous avons décrits ci-dessus tout au long de cet ouvrage… sauf dans le chapitre concernant l'élaboration d'un questionnaire où il sera question de données qualitatives.