Chapitre 2
Agréger Les Données
Par Alistair Croll
Adapté par Arnaud Flan
Quand on souhaite transformer des données en information, le choix des données par lesquelles vous allez commencer est primordial. Les données peuvent être de simples faits — résultat de l’analyse d’un autre contributeur — ou des données brutes. Dans ce cas, tout le travail d’exploration est laissé à l’utilisateur final.

| Niveau d’agrégation | Nombre de métriques | Description |
|---|---|---|
| Fait | Information (contexte maximal) | Information ponctuelle; Pas de possibilité d’aller plus loin |
| Série | Une seule mesure suivant un axe d’analyse | Permet d’analyser l’évolution |
| Séries multiples | Plusieurs mesures ayant au moins un axe en commun | Permet d’analyser l’évolution et la corrélation entre les mesures |
| Séries multiples sommables | Plusieurs mesures ayant au moins un axe en commun | Permet d’analyser l’évolution et la corrélation entre les mesures. Permet de comparer les pourcentages par rapport au total |
| Données résumées | Un enregistrement pour chaque item de la série ; Les mesures sont agrégées | Les items peuvent être comparés entre eux |
| Enregistrements individuels | Un enregistrement par événement | Pas d’agrégation. Analyse jusqu’au niveau le plus fin |
La plupart des données correspondent à un des niveaux définis ci-dessus. Si nous savons par quel type de données nous commençons, nous pouvons grandement simplifier le travail pour obtenir une bonne première visualisation de ces données.
Regardons un par un ces types d’agrégation, en les illustrant par notre exemple sur la consommation de café. Supposons qu’un bar liste chaque tasse de café vendue et enregistre deux informations liées à la vente : le sexe du l’acheteur et le type de café (café noir, décaféiné, ou mocaccino).
Le tableau de données, par année, ressemble à ceciCes données sont des données fictives.:
| Année | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 |
|---|---|---|---|---|---|---|---|---|---|
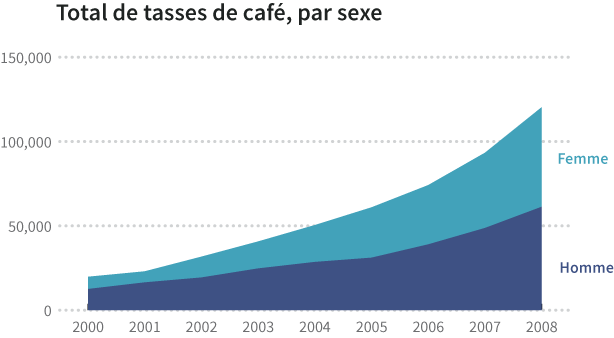
| Total des ventes | 19 795 | 23 005 | 31 711 | 40 728 | 50 440 | 60 953 | 74 143 | 93 321 | 120 312 |
| Homme | 12 534 | 16 452 | 19 362 | 24 726 | 28 567 | 31 110 | 39 001 | 48 710 | 61 291 |
| Femme | 7 261 | 6 553 | 12 349 | 16 002 | 21 873 | 29 843 | 35 142 | 44 611 | 59 021 |
| Café noir | 9 929 | 14 021 | 17 364 | 20 035 | 27 854 | 34 201 | 36 472 | 52 012 | 60 362 |
| Décaféiné | 6 744 | 6 833 | 10 201 | 13 462 | 17 033 | 19 921 | 21 094 | 23 716 | 38 657 |
| Mocaccino | 3 122 | 2 151 | 4 146 | 7 231 | 5 553 | 6 831 | 16 577 | 17 593 | 21 293 |
Fait
Un fait est une information. Il est défini à partir des données, mais choisit de mettre l'accent sur un point particulier.
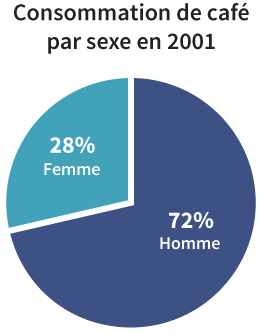
Exemple: en 2000, 36,7% du café a été consommé par des femmes.
Série
Il s’agit d’une information (la variable dépendante) comparée à une autre (la variable indépendante). Souvent, la variable indépendante est le temps.
| Année | 2000 | 2001 | 2002 | 2003 |
|---|---|---|---|---|
| Total des ventes | 19 795 | 23 005 | 31 711 | 40 728 |
Dans cet exemple, le total des ventes de café dépend de l’année. Ici, l’année est indépendante (« prenez une année, n’importe laquelle ») et le total des ventes est dépendant (« basé sur cette année, la consommation de tasses de café est de 23 005 tasses »).
Une série peut aussi être composée de données continues, comme des températures. Considérons ce tableau qui montre le temps pour un adulte avant de souffrir d’une brûlure du premier degré selon la température de l’eau. Ici, la température de l’eau est la variable indépendante.Hémorandum du Gouvernement américain, Commission de Sécurité des Produits de consommation, Peter L. Armstrong, 15 Sept. 1978.:
| Température de l’eau °C (°F) | Délai avant de souffrir d’une brûlure du premier degré |
|---|---|
| 46,7 (116) | 35 minutes |
| 50 (122) | 1 minute |
| 55 (131) | 5 secondes |
| 60 (140) | 2 secondes |
| 65 (149) | 1 second |
| 67,8 (154) | Instantané |
Il peut aussi s’agir d’une série de données non contiguës reliées entre elles par une catégorie comme des marques de voitures, des races de chiens, des légumes ou des planètes du système solaireCentre national de Données de Science Spatial, NASA http://nssdc.gsfc.nasa.gov/planetary/factsheet/planet_table_ratio.html:
| Planète | Masse relative par rapport à la Terre |
|---|---|
| Mercure | 0,0553 |
| Venus | 0,815 |
| Terre | 1 |
| Mars | 0,107 |
| Jupiter | 317,8 |
| Saturne | 95,2 |
| Uranus | 14,5 |
| Neptune | 17,1 |
Dans ces cas, les séries ont une et une seule variable dépendante pour chaque variable indépendante. En d’autres termes, il n’y a qu’un seul total des ventes de café pour chaque année. On les représente généralement en diagramme à barres, en série temporelle, ou en histogramme.
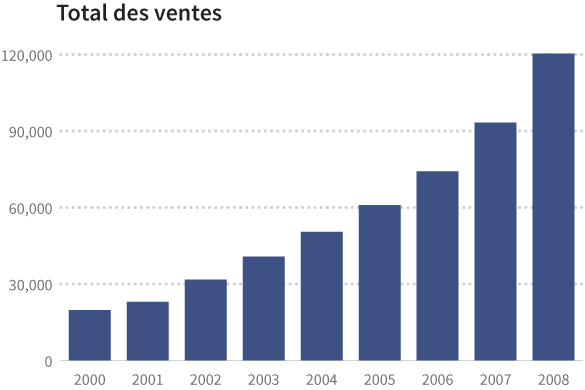
Quand il y a plusieurs variables dépendantes pour chaque variable indépendante, on représente souvent l’information sous forme de nuages de point ou de carte des températures, (aussi appelée carte thermique), ou alors on retravaille les données (calcul d’une moyenne par exemple) pour simplifier ce qu’elles représentent. Nous reviendrons sur ce point plus tard dans ce chapitre dans la section intitulée « Utiliser la visualisation pour révéler les variations cachées ».
Séries multiples
Un jeu de données d’une série multiple se compose de plusieurs variables dépendantes et d’une variable indépendante. Ici, les données concernant l’exposition à l’eau chaude avec des données complémentaires:Hémorandum du Gouvernement américain, Commission de Sécurité des Produits de consommation, Peter L. Armstrong, 15 Sept. 1978.:
| Température de l’eau °C (°F) | Délai avant de souffrir d’une brûlure du premier degré | Délai avant de souffrir d’une brûlure du 2ème et 3ème degré |
|---|---|---|
| 46,7 (116) | 35 minutes | 45 minutes |
| 50 (122) | 1 minute | 5 minutes |
| 55 (131) | 5 secondes | 25 secondes |
| 60 (140) | 2 secondes | 5 secondes |
| 65 (149) | 1 second | 2 secondes |
| 67,8 (154) | Instantané | 1 second |
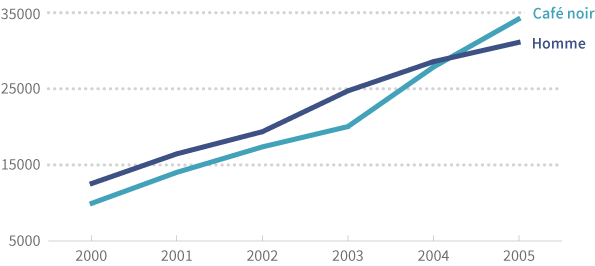
Ou, en reprenant notre exemple sur le café, voici plusieurs séries:
| Année | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 |
|---|---|---|---|---|---|---|
| Homme | 12 534 | 16 452 | 19 362 | 24 726 | 28 567 | 31 110 |
| Café noir | 9 929 | 14 021 | 17 364 | 20 035 | 27 854 | 34 201 |
Ce jeu de données nous indique plusieurs choses sur l’année 2001. Nous savons que 16 452 tasses de café ont été servies à des hommes et que 14 021 tasses de café servies étaient des tasses de café noir (avec caféine, crème ou lait, et sucre).
Nous ne savons toutefois pas comment combiner ces informations dans la mesure où elles ne sont pas reliées entre elles. Nous ne pouvons pas déterminer quel pourcentage des tasses de café noir ont été servies à des hommes ou combien de tasses ont été servies à des femmes.
En d’autres termes, les données de séries multiples sont simplement plusieurs séries présentées dans un seul diagramme ou un seul tableau. On peut les représenter ensemble mais on ne peut pas les comparer ou les combiner.
Séries multiples sommables
Comme leur nom l’indique, les séries multiples sommables sont des séries particulières car segmentées en sous-groupe (genre, type de café).
| Année | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 |
|---|---|---|---|---|---|---|---|---|---|
| Homme | 12 534 | 16 452 | 19 362 | 24 726 | 28 567 | 31 110 | 39 001 | 48 710 | 61 291 |
| Femme | 7 261 | 6 553 | 12 349 | 16 002 | 21 873 | 29 843 | 35 142 | 44 611 | 59 021 |
Puisque nous savons qu’un buveur de café est soit un homme, soit une femme, nous pouvons additionner ces 2 séries pour faire des observations plus larges sur la consommation totale de café. Tout d’abord, nous pouvons calculer des pourcentages.
Ensuite, nous pouvons additionner ces données pour en définir le total:
Un défi avec les données des séries multiples sommables est de savoir quelles séries vont ensemble. Regardons les séries suivantes:
| Année | 2000 | 2001 | 2002 | 2003 | 2004 |
|---|---|---|---|---|---|
| Homme | 12 534 | 16 452 | 19 362 | 24 726 | 28 567 |
| Femme | 7 261 | 6 553 | 12 349 | 16 002 | 21 873 |
| Café noir | 9 929 | 14 021 | 17 364 | 20 035 | 27 854 |
| Décaféiné | 6 744 | 6 833 | 10 201 | 13 462 | 17 033 |
| Mocaccino | 3 122 | 2 151 | 4 146 | 7 231 | 5 553 |
Intrinsèquement, rien dans ces données ne nous dit comment nous pouvons les combiner. C’est l’interprétation humaine des données qui nous permet de savoir que Hommes + Femmes = l’ensemble de la population des buveurs de café et que Café noir + Décaféiné + Mocaccino = tous les cafés (de ce jeu de données). Sans cette connaissance, nous ne pouvons pas combiner ces données ou au pire, nous les combinerions mal.
Il est difficile d’explorer des données résumées
Même si nous connaissons la signification de ces données et que nous réalisons qu’il s’agit de 2 séries multiples séparées (une selon le sexe des consommateurs et l’autre selon le type de café), nous ne pouvons pas les explorer en profondeur. Par exemple, nous ne pouvons pas savoir combien de femmes ont bu un café noir en 2000.
Une erreur commune (mais importante) serait de dire:
- 36,7% des tasses de café ont été vendues à des femmes en 2000.
- Et il y a eu 9 929 tasses de café noir ont été vendues en 2000.
- Donc, 3 642,5 tasses de café noir ont été vendues à des femmes.
Mais c’est faux. Ce type de conclusion ne peut être fait que quand vous savez qu’une catégorie (type de café) est répartie uniformément par rapport à l’autre (sexe). Le fait que le résultat ne soit pas un nombre entier nous rappelle qu’on ne peut pas procéder ainsi (on ne vend pas de demi-tasse de café).
La seule façon de vraiment explorer les données et répondre à de nouvelles questions (comme “Combien de tasses de café noir ont été vendues à des femmes en 2000?”) est de disposer des données brutes. Ensuite, il suffit de savoir comment les agréger de façon appropriée.
Données résumées
Le tableau de données résumées ressemble à ce qu’un point de vente de café pourrait produire. Il présente une colonne d’information catégorielle (genre, H/F) et un sous-total pour chaque type de café. Il inclut également le total de chaque type de café.
| Name | Sexe | Café noir | Décaféiné | Mocaccino | Total |
|---|---|---|---|---|---|
| Robert Durand | H | 2 | 3 | 1 | 6 |
| Marie Sante | F | 4 | 0 | 0 | 4 |
| Philippe Hartin | H | 1 | 2 | 4 | 7 |
| Marie Brasseur | F | 3 | 1 | 0 | 4 |
| Béatrice Condrier | F | 1 | 0 | 0 | 1 |
| Jean Dupond | H | 2 | 1 | 3 | 6 |
| Damien Courtier | H | 3 | 1 | 0 | 4 |
| Suzanne Tremblay | H | 0 | 0 | 1 | 1 |
| Total | 5H, 3F | 16 | 8 | 9 | 33 |
Ce type de tableau est assez familier pour toute personne ayant déjà réalisé une exploration basique de données dans un outil comme Excel. On peut ajouter des totaux :
- Il y a 5 hommes et 3 femmes
- Il y a 16 cafés noirs, 8 décaféinés, et 9 mocaccinos
- Nous avons vendu un total de 33 tasses de café
Mais plus important encore, on peut croiser les données pour répondre à davantage de questions exploratoires. Par exemple : Est-ce que les femmes préfèrent un type de café en particulier ? Excel excelle à faire ce genre de choses, souvent en utilisant un outil appelé tableau croisé dynamique.
Ici un tableau présentant la moyenne du nombre de tasses de Café noir, Décaféiné et Hocaccino consommées par les hommes et les femmes :
| Etiquettes de lignes | Moyenne de café noir | Moyenne de décaféiné | Average of Mocaccino |
|---|---|---|---|
| F | 2,67 | 0,33 | 0,00 |
| H | 2,00 | 1,75 | 2,00 |
| Moyenne pondérée | 2,29 | 1,14 | 1,14 |
En regardant ce tableau, on peut voir clairement que les femmes préfèrent le Café noir et que les hommes se répartissent de façon relativement équitable sur les trois catégoriesLes données ne sont pas suffisantes pour valider statistiquement cette affirmation. Mais ces données sont, de toute façon fictives, alors arrêtez de penser autant à la consommation de café..
Cependant le problème avec ces données, c’est qu’elles sont toujours agrégées d'une façon ou d'une autre. Nous avons résumé les données selon plusieurs dimensions – sexe et type de café – en les agrégeant par nom de client. Bien que ce ne soit pas des données brutes, nous n’en sommes pas éloignés.
Un des bons côtés de l’agrégation est qu’elle permet de conserver des ensembles de données de petite taille. Cela suggère également la façon dont les données peuvent être exploitées. Il est assez courant de trouver des données d’enquête ou de sondage sous cette forme : par exemple, un formulaire Google qui dirait ceci pourrait produire ce type de données :
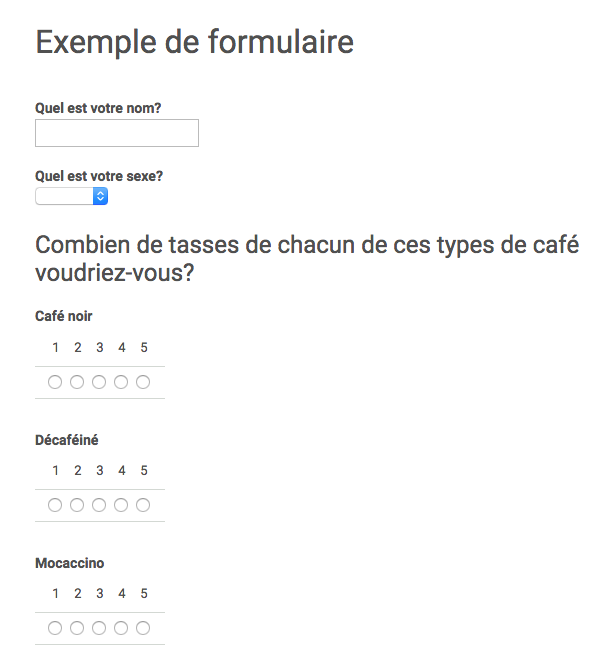
Ce qui permettra de produire les données suivantes dans le tableau Google ci-dessous :
| Date / Heure | Quel est votre nom? | Sexe? | Café noir | Décaféiné | Mocaccino |
|---|---|---|---|---|---|
| 17/01/2014 11:12:47 | Robert Durand | Homme | 4 | 3 |
Utiliser la visualisation pour reveler les variations cachees
Lorsque vous disposez de données résumées ou de données brutes, il est courant de les agréger pour les présenter facilement. En présentant le nombre total de cafés consommés (en sommant les colonnes) ou la moyenne du nombre de tasses par client (moyenne de chaque colonne) on rend les données plus faciles à comprendre.
Prenons le tableau ci-dessous :
| Name | Café noir | Décaféiné | Mocaccino |
|---|---|---|---|
| Robert Durand | 2 | 3 | 1 |
| Marie Sante | 4 | 0 | 0 |
| Philippe Hartin | 1 | 2 | 4 |
| Marie Brasseur | 3 | 1 | 0 |
| Béatrice Condrier | 1 | 0 | 0 |
| Jean Dupond | 2 | 1 | 3 |
| Damien Courtier | 3 | 1 | 0 |
| Suzanne Tremblay | 0 | 0 | 1 |
| Total | 16 | 8 | 9 |
| Moyenne | 2 | 1 | 1,125 |
On peut présenter la moyenne de tasses de café consommées de chaque type de café sous la forme d’un graphique de ce type :
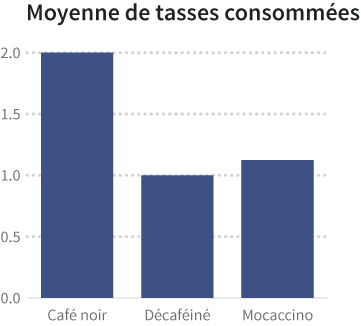
Mais les moyennes cachent des choses. Peut-être que certaines personnes ont consommées une seule tasse et d’autres plusieurs. Il y a plusieurs façons de visualiser la distribution ou la variance de données qui montrent l’information sous-jacente. Parmi celles-ci mentionnons les cartes de températures, les histogrammes, et les nuages de points. En conservant les données sous-jacentes, vous pouvez vous retrouver avec plus d'une variable dépendante pour chaque variable indépendante.
Une meilleure visualisation (par exemple sous forme d'histogramme, qui compte combien de personnes entrent dans chaque plage de valeurs qui composent la moyenne) pourrait révéler que quelques personnes boivent beaucoup de café, et un grand nombre de personnes en boivent en petite quantité.
Prenons cet histogramme du nombre de tasses par client. Tout ce que nous avons fait a été de dénombrer combien de personnes avaient consommé une tasse, combien en avaient consommé deux, combien en avaient consommé trois, et ainsi de suite. Puis nous avons tracé la fréquence de chaque nombre, ce qui explique pourquoi ce type de graphique s’appelle un histogramme de fréquence.
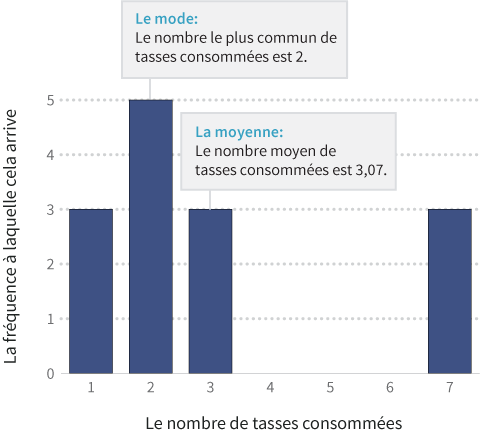
Le nombre moyen de tasses dans cet ensemble de données est d'environ 3. Et lemode, ou nombre le plus fréquent, est de 2 tasses. Mais comme le montre l'histogramme, il existe trois grands consommateurs de café qui ont chacun consommé 7 tasses, poussant la moyenne vers le haut.
En d'autres termes, lorsque vous avez des données brutes, vous pouvez voir les exceptions et les valeurs aberrantes et vous racontez une histoire plus précise.
Même ces données, verbeuses et informatives, ne sont pas des données brutes : elles sont toujours agrégées.
L'agrégation se produit dans de nombreux cas. Par exemple, un reçu de restaurant regroupe habituellement les commandes par table. Il n'y a pas moyen de connaitre ce qu'un individu à la table a commandé pour le dîner, seulement les plats qui ont été servis à la table et ce qu'ils coûtent. Pour réaliser une exploration vraiment détaillée, nous avons besoin de données au niveau de la transaction.
Enregistrements individuels
Chaque enregistrement de transactions « capture » des informations sur un événement spécifique. Il n'y a pas d'agrégation des données quel que soit la dimension comme le nom du client (même si son nom peut ne pas être « capturé »). Il n’est pas modifié au fil du temps; c’est un instantané.
| Date / Heure | Name | Sexe | Coffee |
|---|---|---|---|
| 17:00 | Robert Durand | H | Café noir |
| 17:01 | Marie Sante | F | Café noir |
| 17:02 | Philippe Hartin | H | Mocaccino |
| 17:03 | Marie Brasseur | F | Décaféiné |
| 17:04 | Béatrice Condrier | F | Café noir |
| 17:05 | Jean Dupond | H | Café noir |
| 17:06 | Damien Courtier | H | Café noir |
| 17:07 | Suzanne Tremblay | H | Mocaccino |
| 17:08 | Robert Durand | H | Café noir |
| 17:09 | Marie Sante | F | Café noir |
| 17:10 | Philippe Hartin | H | Mocaccino |
| 17:11 | Marie Brasseur | F | Café noir |
| 17:12 | Jean Dupond | H | Décaféiné |
| 17:13 | Damien Courtier | H | Café noir |
Ces enregistrements peuvent être agrégés selon chacune de ces colonnes. Les données temporelles peuvent également être regroupées (par heure, jour ou année). En fin de compte, l'ensemble de données initiales de la consommation de café par année que nous avons vu résulte de ces données brutes.
Décider comment agréger
Lorsque nous regroupons des données dans des catégories ou que nous les transformons de quelque façon qu’il soit, nous enlevons de l’information brute. Par exemple, quand nous avons transformé les transactions brutes en totaux annuels:
- Nous avons anonymisé les données en supprimant les noms des clients en les regroupant.
- Nous avons regroupé les données temporelles en les résumant par année.
Chacune de ces données aurait pu nous montrer que quelqu'un était un grand buveur de café (en se basant sur la quantité de café consommée par une personne, ou sur la base du niveau de consommation par jour). Alors que nous ne pensons pas aux conséquences de nos données sur la consommation de café, supposons que les données se rapportent plutôt à la consommation d'alcool ? Aurions-nous une obligation morale de prévenir quelqu'un si l’exploitation des données montrait qu'une personne boit habituellement beaucoup d'alcool ? Que faire si cette personne tue quelqu'un alors qu'il conduit en état d'ébriété ? Est-ce que les données sur la consommation d'alcool sont sujettes à des contraintes juridiques différentes des données sur la consommation de café ? Sommes-nous autorisés à regrouper certains types de données, mais pas d'autres ?
Peut-on traiter les biais inhérents à la manière d’agréger les données avant de les présenter ?
Le mouvement autour du stockage massif de données (Big Data) va résoudre certains de ces biais. En premier lieu, stocker toutes les transactions brutes était techniquement très compliqué. Nous avions à décider comment agréger les choses au moment de la collecte et jeter l'information brute. Mais les progrès dans le stockage, les traitements massivement parallèles, et l'informatique en nuage (cloud computing) font de l’agrégation à la volée de vastes ensembles de données une réalité, qui devrait surmonter un certain nombre de biais d'agrégation.