Chapitre 7
Préparer les données pour le nettoyage
Par Oz du Soleil
Adapté par Youssef Ennahdi
Il est difficile d’apprendre et d’enseigner à préparer ses données pour qu’elles soient utiles. Certaines opérations préparatoires sont requises, particulièrement si vous travaillez avec des données que vous n’avez pas collectées vous-mêmes. Bien que beaucoup de ces actions soient automatisables, un travail manuel est souvent nécessaire, ne serait-ce que pour bien définir les tâches à accomplir durant la préparation des données. C’est pour cette raison que certains détestent cette partie du travail...mais quelqu’un doit bien s’en occuper !
Que vous soyez un analyste travaillant sur des milliards de données ou sur une simple liste de 90 contacts, vous ferez certainement face, à un moment ou à un autre, à des données “sales”. Malheureusement, la préparation des données n’est pas toujours facile et il n’y a d'ailleurs pas qu’une seule manière de s’y prendre. Chaque jeu de données est unique et vous n’utiliserez peut-être certaines techniques qu’une seule fois dans votre carrière, comme vous le verrez dans les exemples suivants.
Séparer les données
La première phase de préparation consiste à séparer les données en champs que vous pourrez utiliser facilement par la suite.
Avez-vous déjà reçu un ensemble de données dans lequel vous ne pouviez pas directement récupérer les informations dont vous aviez besoin ? Peut-être qu’une liste d’adresses ne provenait que d’un seul champ (no.civique, ville et pays dans la même entrée), vous empêchant ainsi de tirer des statistiques sur les villes et les pays. Ou alors, un fournisseur vous a envoyé une liste d’inventaire contenant 6000 pièces numérotées, mais son système de numérotation combinait code d’entrepôt et numéro de pièce alors que vous n’aviez besoin que des numéros de pièce.
| Vous voulez | Ils fournissent |
|---|---|
| C77000S | GA3C77000S |
| W30000P | GA1W30000P |
| D21250G | DE1D21250G |
Considérez les problèmes présents dans le jeu de données suivant:
| Centre marchand | Adresse | Ville | Région |
|---|---|---|---|
| Warm Willows Centre marchand Peters Road Marrison, MI | |||
| Jaspers Martinson & Timberlake Rds Reed, FL | |||
| Lara Lafayette Shoppes 17 Industrial Drive Elm, CT |
Vous voudriez que le nom du centre marchand, son adresse, sa vielle et sa région soient entreposés dans des champs différents. Le jeu de données contient des centaines d’enregistrements et les diviser manuellement prendrait beaucoup de temps. Les centres marchands sont écrits en caractères gras, ce qui facilite la distinction entre la fin de leurs noms et le début des adresses. Toutefois, comme les adresses ne commencent pas toutes par des chiffres, on ne peut pas utiliser un outil standardisé pour les séparer des noms. On pourrait écrire un programme qui distinguerait le texte écrit en caractères gras pour le séparer du reste. Comme ce type d’entrée est rare, il est probable qu’un tel programme ne serve qu’une seule fois.
Nonus ne pouvons pas vous enseigner tout ce qu’il y a à savoir sur la séparation de données dans ce chapitre car chaque cas est unique. Cependant, il existe des techniques qui sont utiles dans plusieurs situations. Nonus vous montrerons certaines d’entre elles et aborderons certains défis (et leurs causes) afin de vous mettre sur la bonne voie.
Allons-y
Un exemple simple rencontré par plusieurs est la séparation des noms de famille et des prénoms. Vous recevrez peut-être un jeu de données où les noms complets existent dans un champ alors que vous avez besoin d’avoir des noms de familles et prénoms séparés, ou alors la séparation a déjà été effectuée mais certains enregistrements contiennent les deux informations dans un seul de ces champs.
Dans un seul champ:
|
Deux champs, mais l’information n’est pas toujours correcte:
|
Quand nous recevons de telles données, le problème semble facile à résoudre. Il existe une manière triviale de séparer les prénoms et noms de famille pour Marc, Fumi et Émile: on recherche d’abord le caractère espace entre les deux mots et on coupe la donnée en deux. Voilà!
C’est assez simple en théorie, mais en pratique, tout se complique rapidement. Que faire, par exemple, si votre ensemble de données contient des milliers d’enregistrements ? Vous passerez beaucoup de temps à diviser les noms manuellement et il y a potentiellement beaucoup plus de cas posant problème que simplement la concaténation du prénom et du nom de famille. Le tableau suivant en énumère quelques-uns.
| Initiales | Jean M. Le Clezio |
| Désignation professionnelle | Léo Carson, Directeur |
| 2-part Nonm de familles | Charles de Gaulle |
| Préfixes | Dr Herman Wilheim |
| Suffixes | Jean-Marie Cusson Junior |
| Hyphenated Nonm de familles | Julie Baker-Andersen |
| Nonm de famille First | Kincaid, Paul |
| Prénom composé | Pierre Paolo Lipscomb |
| Préfixes et Suffixes | Dr Léon St-André-Fernandez Junior |
| Autres champs non désirés inclus | Edgar Murray 465 Rue de l’Armée |
| Prénom absent | Drolet |
| Non/Missing Nonm de famille | Lison |
| Information manquante (aucun nom!) | |
| Aucune idée! | JJ |
| Pas un nom de personne! | Nonrth Ville Garden Supply |
L’heure des décisions
Supposons que nous ayons à séparer les noms de manière à pouvoir les classer par nom de famille et que notre liste contienne 500 noms (trop longue pour être modifiée à la main).
Avant de commencer, nous devons en apprendre davantage :
- Pourquoi est-il si important d’ordonner la liste finale selon ce champ spécifique? Avoir les noms complets dans un seul champ pose-t-il problème ?
- À quoi doit ressembler le résultat ?
- Est-il important de garder « Dr » et de créer un champ supplémentaire pour les titres tels que « Mgr » (Monseigneur), « Me » (Maître), etc ?
- Les particules (par exemple Junior) doivent-elles rester avec le patronyme ou doit-on créer un nouveau champ ?
- Doit-on garder les initiales ? Dans un champ qui leur est propre ? Avec le prénom ? Avec le nom de famille ?
- Veut-on garder les désignations professionnelles ?
- Le jeu en vaut-il la chandelle? Pour les cas les plus simples, vous pourriez utiliser une tierce personne pour effectuer ce travail, mais cela n’est peut-être pas idéal pour les cas plus complexes. Que répondre si un professionnel vous demande 1000 dollars pour réaliser ce travail ?
- Que faire des entrées incomplètes ou incorrectes ?
Les réponses devront être fournies avant de commencer à travailler sur vos données. Prendre ces décisions peut réellement rendre le procédé plus facile. Par exemple, si vous décidez que les désignations professionnelles n’ont aucune importance, il y a peut-être une manière simple de s’en débarrasser et faciliter d’autres parties du projet.
Supposons que vous travaillez sur une liste de 20 000 noms, 19 4000 viennent de France et 600 de Turquie. Les titres honorifiques en France viennent avant le nom (par exemple, Dr Jean Dupont), alors qu’ils sont placés après celui-ci en Turquie (par exemple, Li Tintonpor Dr). Vous essayez de savoir s’il faut créer un nouveau champ pour les noms turcs ou carrément créer un nouveau jeu de données. Vous demandez au client.
Sa réponse est simple. Ils ne font pas d’affaires en Turquie et ne tiennent pas particulèrement à conserver ces enregistrements. Vous pouvez donc les effacer. Et voilà! plus que 19 400 noms à traiter.
Comment séparer ces données?
Il y a tellement de techniques que nous pourrions écrire un livre entier sur ce seul sujet. Vous pourriez diviser les informations dans Excel, ou, si vous avez des connaissances en programmation, vous pourriez utiliser Python, SQL, ou n’importe quel autre langage pour séparer les données. Il y a trop de choses à présenter pour que nous puissions les couvrir dans ce chapitre, mais pour une bonne liste de références, veuillez consulter notre appendice. Pour l’instant, nous nous contenterons de couvrir les techniques de base de manière à vous préparer à utiliser ces références quand vous serez prêt.
Commencez toujours par faire une copie de vos données avant de commencer leur préparation ou leur nettoyage de manière à vous référer à la version originale si l’un de vos changements s’avérait incorrect.

COMMENCEZ EN BAS
La plupart du temps, la donnée qu’il faut séparer est assez simple. Prenons une liste de 500 noms. De ces 500 noms, vous découvrirez peut-être que 200 d’entre eux n’ont aucun problème; ils présentent un prénom et un nom de famille séparté par un espace. Mettez-les de côté. N’y touchez pas. Puis tournez-vous vers les 300 autres.
IDENTIFIEZ LES ANOMALIES
Cherchez dans le jeu de données les entrées sans information, les noms compliqués, les noms incomplets, les noms qui ne sont pas des noms d’individus et tous les enregistrements que vous ne savez pas comment traiter. Mettez-les de côté. Nonus supposerons que cela correspond à 40 noms.
CHERCHER LES SIMILARITÉS
Des 260 noms restants, peut-être que 60 sont complexifiés par du charabia professionnel après le nom proprement dit. Que vous effaciez ces qualifications professionnelles ou que vous les mettiez dans leur propre champ séparé du nom complet, faites la modification en une seule fois. Désormais, ces désignations professionnelles sont séparées (ou effacées) et votre champ ne contient plus qu’un prénom et un nom de famille séparé par un espace. Ces 60 entrées peuvent être ajoutées aux 200 noms que nous avons identifiés au début du traitement.
Nonus mettrons les noms à particules et autres types particuliers dans des groupes à part.
EFFORT MANUEL
Les 40 anomalies identifiées au commencement peuvent potentiellement être corrigées manuellement.
Parfois, quand nous traitons des données, certains problèmes disparaissent d’eux-même lorsque nous portons attention aux données. Par exemple, un enregistrement sans information peut simplement être le duplicata d’un autre enregistrement qui lui est complet. Dans ce cas, nous pouvons simplement effacer l’entrée erronée et passer à la suite.
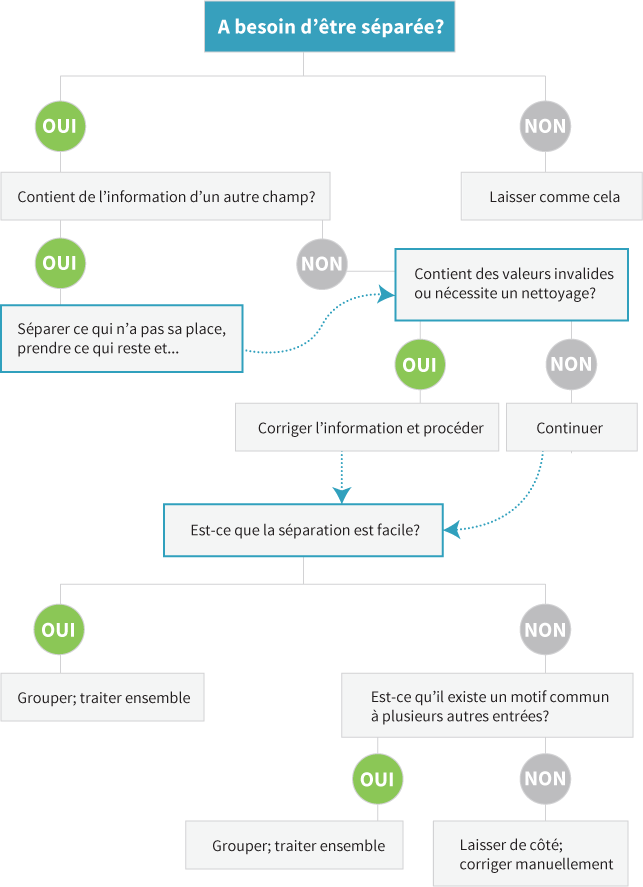
Problèmes communs
Dépendant de la façon dont les donnée ont été collectées, il y a d’autres champs qu’il sera intéressant de diviser en même temps que vous séparez les noms. Les plus communs sont :
-
Adresses
-
Numéros de téléphone, surtout si vous désirez avoir l’indicatif séparé
-
Courriels, si les informations de domaine vous intéressent
-
Dates, si vous voulez seulement l’année ou le mois
UNITÉS DE MESURE ET CONVERSION
Une autre tâche importante durant la préparation des données est de s’assurer que toutes les valeurs d’un même champ ont la même unité. Idéalement, vous aurez spécifié l’unité dans le formulaire de saisie, mais vous travaillez peut-être avec les données d’un tiers ou des données provenant de différentes sources (par exemple, données provenant de mesures faites par des machines dans des unités différentes). Imaginez que, vous travaillez sur des fichiers médicaux de différents pays et les poids des patients sont exprimés en livres dans certains cas et en kilogrammes dans d’autres. Il est important de convertir toutes les valeurs soit en livres soit en kilogrammes de manière à ce qu’elles existent dans une même échelle de valeurs. Sans cette conversion, les enregistrements ne pourront être comparés directement et toute visualisation basée sur les données originales aura une drôle d’allure !
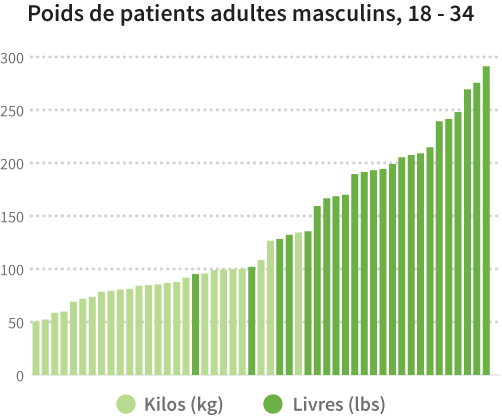
Passez rapidement en revue les valeurs de votre jeu de données afin d’identifier tout champ pouvant présenter plusieurs unités et déterminer si des conversions sont nécessaires. Si elles le sont, vous pourriez avoir besoin de référencer un champ supplémentaire identifiant les unités d’origine contre lesquelles les conversions ont été faites et quels enregistrements ont été changés. Si aucun champ ne vous indique les unités utilisées, d’autres champs, comme la localisation géographique, peuvent aider. Si vous ne trouvez pas de champ pouvant vous aider à identifier les unités mais que vous soupçonner la nécessité d’une conversion, contactez le fournisseur originel des données afin d’obtenir cette information. Vous découvrirez peut-être qu’aucune conversion n’est nécessaire et que vos données sont juste étranges. Il vaut toutefois mieux vérifier et s’en assurer plutôt que de passer à côté d’une erreur.
Un autre type de conversion qui semble parfois moins évident concerne le type de données. Il est important de s’assurer que toutes les valeurs d’un même champ sont du même type sinon votre visualisation risque de ne pas s’afficher correctement, selon la manière dont votre logiciel interprète cette information. Par exemple, «80» est probablement un nombre pour vous, mais votre ordinateur le sauvegarde réellement sous forme d’une chaîne de caractères plutôt que sous forme numérique. Certains logiciels de visualisation traiteront tout de même une entrée de texte contenant un nombre comme un nombre, mais d’autres ne le feront pas. Une bonne pratique est donc de sauvegarder chacun de vos champs (ou variables) sous un seul type de donnée, tel que texte ou numérique. Ainsi, toute information contenue dans ce champ sera traitée comme elle se doit.
CONTRÔLER LES INCONSISTANGIS
L’une des tâches les plus fastidieuses quand on nettoie des données est la gestion d’informations fluctuantes. Par exemple, il est fréquent de rencontrer des mots provenant de plusieurs langues différentes dans un même jeu de données. Avec l’internet, il est maintenant facile de recueillir des informations venant d’utilisateurs du monde entier. Cela peut causer des problèmes quand vous essayez de grouper les informations dans le but de les visualiser. Imaginez que vous faites un sondage auprès d’’étudiants et que l’un de vos champs textuels leur demande leur matière d’étude principale. Un étudiant répondra « Maths » alors qu’un autre y écrira « Mathématiques » et un troisième « Mathématiques Appliquées ». Ces réponses correspondent à la même matière principale sur un campus, mais un ordinateur ou un logiciel de visualisation ne mettra pas ces réponses dans le même groupe. Vous devrez créer un seul terme (par exemple, changer toutes ces réponses pour qu’elles soient « Maths » ou « Mathématiques ») ou créer un champ séparé contenant un code si vous souhaitez les voir traiter comme appartenant toutes à la même catégorie.
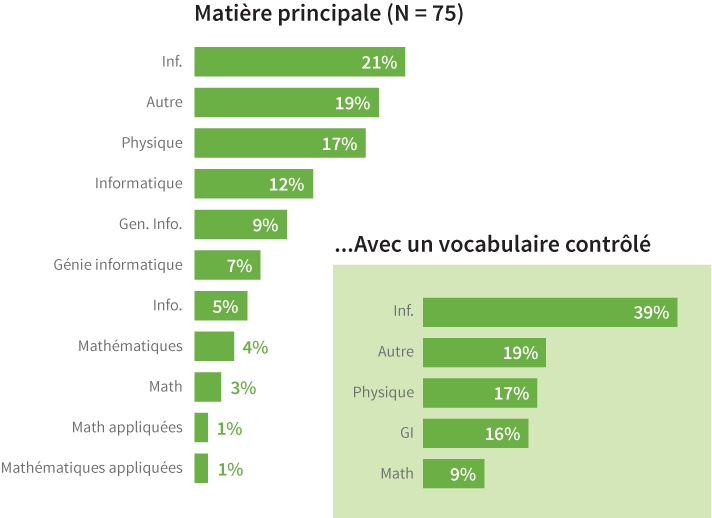
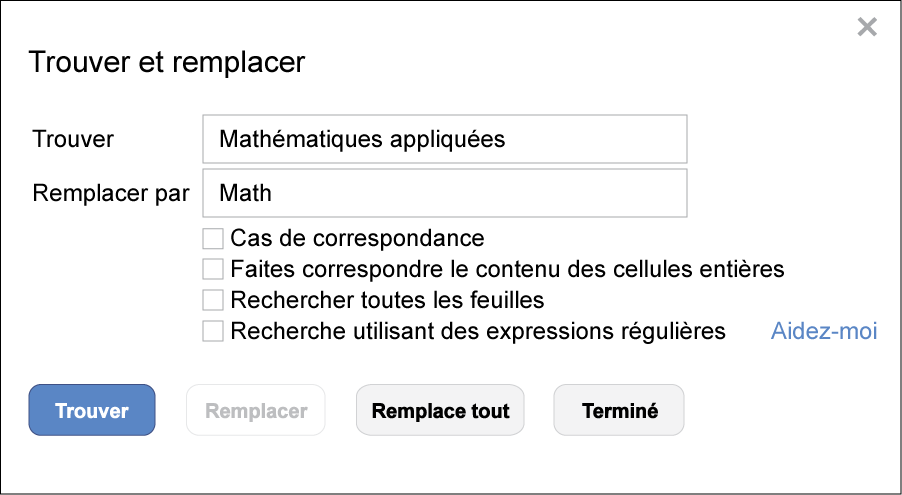
Bien qu’un ordinateur puisse vous aider à changer les valeurs, les problèmes liés à l’inconsistance des données doivent souvent être traitées semi-manuellement. Si vous utilisez des champs textuels, comme cela arrive souvent lorsqu’on programme, les outils de recherche et de remplacement seront vos meilleurs amis. Tant que vous savez quelles sont les variantes principales des données que vous désirez contrôler, vous pourrez rapidement toutes les remplacer par une même et simple valeur.
VALEURS MANQUANTES
Un des problèmes les plus frustrants apparait quand des champs de données sont vides ou incomplets. Si une donnée n’a pas été collectée, il n’est pas certain que vous puissiez retourner à la source pour la retrouver. Il est aussi possible que la source ne soit pas connue, comme dans le cas de sondages anonymes. Si vous ne pouvez pas récupérer cette information, il est important de gérer les cas de données manquantes correctement. Vous devrez prédéfinir une liste de valeurs à entrer quand des données sont manquantes de façon à ce qu’un tiers vérifiant votre jeu de données sache que les informations sont absentes et que ce n’est pas un oubli de votre part.
Ces valeurs devront être hors du domaine normal de vos données afin qu’il soit clair qu’elles remplacent des informations manquantes. Pour des ensembles de données sans nombres négatifs, la valeur « -9 » est souvent utilisée comme valeur par défaut, du moins dans les champs numériques. « 999 » est un autre choix populaire pour les ensembles n’utilisant que des petits nombres et un point (.) est utilisé par certains logiciels statistiques traitant des jeux de données avec des nombres négatifs ou représentant de grandes valeurs. Pour les champs textuels, le signe moins (-) est communément utilisé pour indiquer une valeur manquante.
Gardez en mémoire qu’une valeur manquante n’est pas la même chose qu’un déni de réponse intentionnel. Dans les deux cas, vous n’avez pas de réponse à la question posée, mais lorsqu’une personne choisit activement de ne pas répondre, cela est en soi une information. Ces réponses ne sont pas manquantes : vous savez parfaitement où elles se trouvent, les sondés ne veulent tout simplement pas vous fournir l’information. Comme discuté dans le chapitre sur la conception de formulaire, il vaut mieux introduire une option « Préfère s’abstenir » pour les questions personnelles, telles que celles concernant les revenus, l’affiliation politique, etc. Ainsi, vous pouvez utiliser un code pour ce type de réponse et lors des révisions ultérieures de votre jeu de données, vous saurez différencier les abstentions des cas où l’information est réellement manquante.
Il faut se rappeler que pour les représentations visuelles descriptives simples, les données manquantes sont décrites en incluant une catégorie sans-réponse ou en signifiant un changement dans la taille de l’échantillon. Cependant, en statistiques inférentielles, les données manquantes peuvent être traitées de bien des manières, de l’exclusion à l’imputation en passant par les méthodes de classification automatique tel que l’algorithme espérance-maximisation.
RÉDUIRE LA CHARGE DE LA PRÉPARATION DES DONNÉES
Les meilleurs remèdes sont préventifs. Si vous êtes la personne qui crée le formulaire d’entrées-utilisateur, faites ce que vous pouvez pour éviter de recevoir des données qui nécessiteront un travail intensif durant les phases de préparation des données. Dans le chapitre sur les types de validation des données, nous discuterons des différentes stratégies pour minimiser le nombre de tâches de préparation des données à réaliser.
Si vous n’êtes pas la personne qui collecte les données mais que vous pouvez discuter avec ceux qui le font, essayez de travailler avec eux afin d’identifier et de résoudre tous les problèmes de collection en utilisant les différentes stratégies présentées dans le chapitre sur les types de validation des données comme guide.
APRÈS LE NETTOYAGE DES DONNÉES
Une fois vos données séparées dans les champs voulus, converties dans les bonnes unités et dans les bons types et que la terminologie est sous contrôle, vous êtes enfin prêt à passer à la phase de nettoyage des données où vous vérifierez la validité factuelles de celles-ci. Dans les trois chapitres suivants, nous parlerons du processus de base de nettoyage des données, des différents processus permettant de valider les informations et d’y déceler des problèmes, et de ce que vous pouvez et ne pouvez pas faire lors du nettoyage des données.